고정 헤더 영역
상세 컨텐츠
본문
2주차에서 제일 중요하다고 느낀건 전처리였다.
데이터 전처리
다량의 데이터에서 필요없는 데이터를 지우고 필요한 데이터만을 취하기 위함.
예) null값을 삭제, 정규화, 표준화 등
정규화
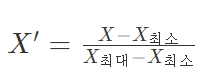
이런 수식이 있긴한데, 사실 수식은 필요없긴하다.
정규화는 데이터를 0과 1사이의 범위를 가지도록 하기 위함.
표준화
는 데이터의 분포를 정규분포로 바꿔줌. 데이터의 평균이 0이 되고 표준편차가 1이 되는 것이다.
3주차
딥러닝
지금까지는 선형관련 문제만 공부했는데, 사실상 선형문제는 얼마없음.
데이터 셋을 작은 단위로 쪼개는데, 이 단위가 배치(Batch)
데이터 셋을 쪼개고 몇차례 반복과정을 하는데, 이 반복과정이 이터레이션(Iteration)
보통 머신러닝에서는 똑같은 데이터셋을 가지고 반복 학습을 하는데, 100번 반복학습을 하면 100 에폭(epochs)
과적합(Overfitting) 과소적합(Underfitting)
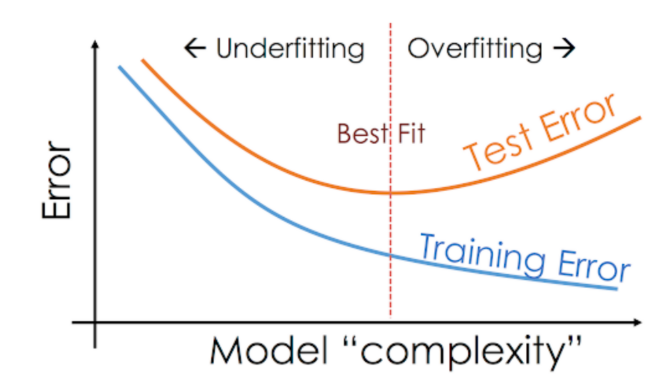
위 그래프와 같이 딥러닝 하다보면 Training Error는 낮아지는데 Validation loss가 높아지는 시점이 발생함.
그 때 저 Best Fit을 찾는게 중요하다.




